---
license: mit
language:
- zh
- en
base_model:
- zai-org/GLM-4.1V-9B-Base
pipeline_tag: image-text-to-text
library_name: transformers
---
WebVIA: A Web-based Vision-Language Agentic Framework for Interactive and Verifiable UI-to-Code Generation
- **Repository:** https://github.com/zheny2751-dotcom/WebVIA
- **Paper:** https://arxiv.org/pdf/2511.06251
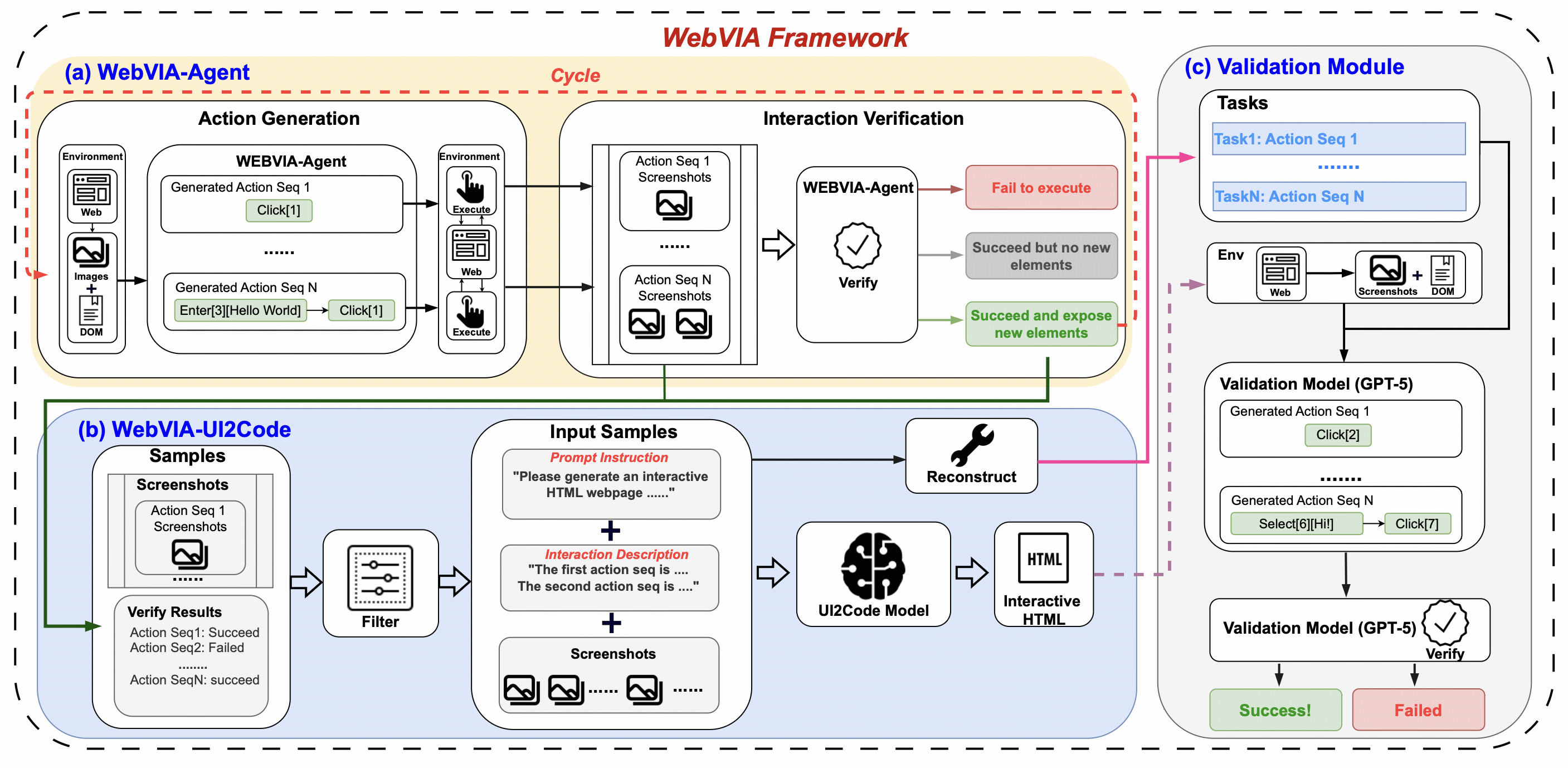
**WebVIA** is **the first agentic framework** for interactive and verifiable UI-to-Code generation. While prior vision-language models only produce static HTML/CSS layouts, WebVIA enables executable and interactive web interfaces.
The framework consists of three modules:
- WebVIA-Agent – navigates websites and captures multi-state UI screenshots.
- WebVIA-UI2Code – generates functional HTML/CSS/JavaScript code with interactivity.
- Validation Module – verifies whether the generated UI behaves as expected.
### Backbone Model
Our model is built on [GLM-4.1V-9B-Base](https://huggingface.co/zai-org/GLM-4.1V-9B-Base).
### Quick Inference
This is a simple example of running single-image inference using the `transformers` library.
First, install the `transformers` library:
```
pip install transformers>=4.57.1
```
Then, run the following code:
```python
from transformers import AutoProcessor, AutoModelForImageTextToText
import torch
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://raw.githubusercontent.com/zheny2751-dotcom/UI2Code-N/main/assets/example.png"
},
{
"type": "text",
"text": "Based on the domtree and the page screenshot, please identify which interactive components in the image require interaction. Please note that if similar buttons have been clicked on similar pages in the past, do not click them again, and also do not select buttons that are obscured on the page."
}
],
}
]
processor = AutoProcessor.from_pretrained("zai-org/WebVIA-Agent")
model = AutoModelForImageTextToText.from_pretrained(
pretrained_model_name_or_path="zai-org/WebVIA-Agent",
torch_dtype=torch.bfloat16,
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=16384)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
```
See our [Github Repo](https://github.com/zheny2751-dotcom/WebVIA) for more detailed usage.
## Citation
If you find our model useful in your work, please cite it with:
```
@article{xu2025webvia,
title={WebVIA: A Web-based Vision-Language Agentic Framework for Interactive and Verifiable UI-to-Code Generation},
author={Xu, Mingde and Yang, Zhen and Hong, Wenyi and Pan, Lihang and Fan, Xinyue and Wang, Yan and Gu, Xiaotao and Xu, Bin and Tang, Jie},
year={2025},
journal={arXiv preprint arXiv:2511.06251}
}
```